



AngularJS: How to create a SPA crawlable and SEO friendly?
AUG 23, 2015
If you're using Angular, probably you already know about ngRoute and the amazing benefit of avoiding full page reloads and requesting just what you need when you click to change to another page. If so, you need to be aware about how search engines will see your website and how you can help them to properly index your content.
What is SPA?
SPA stands for Single-Page Application. Its usage is growing in a fast pace since it enables the website to provide a more fluid user experience. When a page is loaded, you can browse other links and load new content without the need of a full page reload. Only one piece of the page is discarded and replaced by the content of the next page. With this, you will avoid requesting all JavaScript and CSS files again and rendering your header and footer HTML.
For example, this blog was created using the Angular ngRoute directive. If you try to change to another blog post, you can see that the header content will not flash and the post will load very fast.
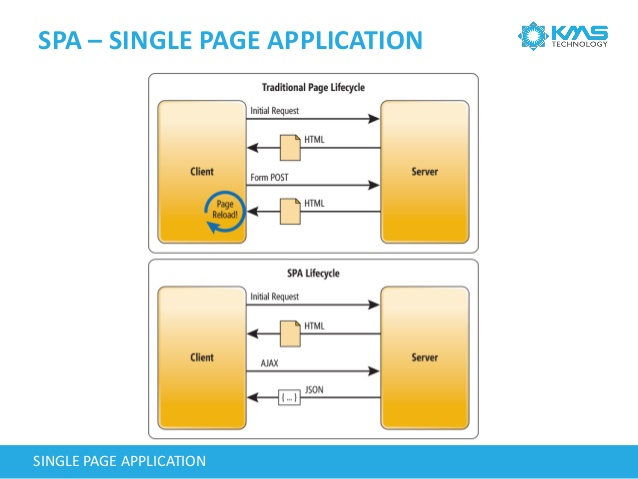
However, this approach have some drawbacks, but all of them can be handled in some way. What I'm focusing in this post is how to help the search engines, like Google, to properly index your content and make it searchable.
SEO and Crawlable Pages
SEO stands for Search Engine Optimization. What we are trying to achieve here is a way to help search engines to render your page and understand your content.
Search engines uses web crawlers to systematically browse web pages to collect information and to index them based on its contents. The main issue here is that most of the web crawlers don't execute JavaScript code and can't see what your SPA retrieves with each link. I've said most web crawlers. Fortunately, Google is currently prepared to execute JavaScript code. This make your task much easier, as you can see in the following section, but it have some drawbacks.
Crawlable Pages for Google
If you believe that being googleable is enough for your website, then you don't need to modify anything. Since Googlebots will execute your JavaScript, your page contents and links will be available for them.
However, Google recognizes that some JavaScript code may not be executed if its too complex or arcane. So, what you can do to help Google (and every crawler), is to add a Sitemap file named sitemap.xml at your web server root directory to tell crawlers what links do you have in your website. Also, note that you can include "invisible links", like the ones that just appears after you fill a form.
In this blog, I've added the following sitemap.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="https://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://zanon.io/</loc>
<lastmod>2015-08-23</lastmod>
<changefreq>weekly</changefreq>
</url>
<url>
<loc>https://zanon.io/posts/angular-how-to-create-a-spa-crawlable-and-seo-friendly</loc>
<lastmod>2015-08-23</lastmod>
<changefreq>monthly</changefreq>
</url>
</urlset>
Note: if you want your site to be correctly rendered in Facebook's preview or Twitter's cards, then you need to pre-render your pages. In this case, being just googleable is not enough. Another problem is that Google may index your content without parsing variables. For example, you can see things like {{ myVar }} in search results instead of the actual content.
Crawlable Pages for Bing and Others
For crawlers that aren't able to execute JavaScript code, you need to pre-render the page and make it available for them. Also, the Sitemap should be referencing those pre-rendered pages for an extra help.
The first step is to choose: do you want to pre-render all pages upfront or on the fly?
Pre-rendering on the fly
Some frameworks, like Prerender, acts like a middleware checking each request to see if it's a request from a crawler. If it is, a static HTML version of the page will be generated and send as the answer.
It is a nice solution and widely used, but in Amazon S3, you don't have a CPU server to process those requests on the fly, so I'll give more details using the following approach.
Pre-rendering at deployment time
Google has defined years ago some conventions about how his crawlers should handle SPA websites. Those conventions were accepted and followed by Bing and others. What this article describes is some guidelines that you need to follow to offer the crawler a static and pre-rendered version of your site. If you follow the guidelines and have a link like www.example.com/#!contact, the crawler will send a GET request to www.example.com/?_escaped_fragment_=contact. If you have a pretty URL design without the hashbang, like www.example.com/contact, and adds a meta tag to inform that your page is a fragment, the GET request will target the www.example.com/contact?_escaped_fragment_= address.
With this approach, what you need to do is write a server rewrite rule to treat all requests with this ?_escaped_fragment_= code and point those requests to another address like snapshots/contact.html that contains your pre-rendered page.
However, if you're using Angular, you don't need to follow those guidelines and prepare a server rewrite rule. Furthermore, if your app is hosted in Amazon S3, you'll not be able to make it work since Amazon S3 (and Amazon CloudFront) does not offer a URL rewrite option and their URL redirects options are limited.
To make your site crawlable, the easiest solution, and the only available for static websites, is to pre-render all of your webpages, even your index.html, and upload them following your website paths.
Since a user browsing the webpage has JavaScript enabled, Angular will be triggered and will take control over the page which results into a re-rendering of the template. With this, all Angular functionalities will be available for this user.
Regarding the crawler, the pre-rendered page will be enough.
Example
If you have a website named www.myblog.com and a link to another page with the URL www.myblog.com/posts/my-first-post. Probably, your Angular app has the following structure: an index.html file that is in your root directory and is responsible for everything. The page my-first-post is a partial HTML file located in /partials/my-first-post.html.
The solution in this case is to use a pre-rendering tool at deploy time. You can use Phantomjs for this and I'll tell how later.
You need to use this pre-render tool to create two files: index.html and my-first-post. Note that my-first-post will be an HTML file without the .html extension, but you will need to set its Content-Type to text/html when you upload to Amazon S3.
You will place the index.html file in your root directory and my-first-post inside a folder named posts to match your URL path /posts/my-first-post.
With this approach, the crawler will be able to retrieve your HTML file and the user will be happy to use all Angular functionalities.
Note: this solution requires that all files be referenced using the root path. Relative paths will not work if you visit the link www.myblog.com/posts/my-first-post.
By root path, I mean:
<script src="/js/myfile.js"></script>
The wrong way, using relative paths, would be:
<script src="js/myfile.js"></script>
Pre-rendering with Phantomjs
PhantomJS is a headless browser that can be used to GET a page URL and output its rendered HTML result. The solution here would be to automate this task so every time you need to make a new deploy, a PhantomJS task would be called to render the HTML pages and output the results in the expected path.
After installing this tool, create a JavaScript file named prerender.js with the following content:
var fs = require('fs');
var webPage = require('webpage');
var page = webPage.create();
// since this tool will run before your production deploy, your target URL will be your dev/staging environment (localhost, in this example)
var pageName = 'angularjs-how-to-create-a-spa-crawlable-and-seo-friendly';
var path = 'posts/' + pageName;
var url = 'http://localhost/' + path;
page.open(url, function (status) {
if (status != 'success')
throw 'Error trying to prerender ' + url;
var content = page.content;
fs.write(path, content, 'w');
console.log("The file was saved.");
phantom.exit();
});
To execute this test, execute the following:
> phantomjs prerender.js
The output file will be ready for deployment.
UPDATE: Sep 06, 2015
Updated this post adding more info about Amazon S3 and the example with Phantomjs.